|
1
|
- Scott S. Emerson, M.D., Ph.D.
- Professor of Biostatistics,
- University of Washington
- May 1, 2004
|
|
2
|
- Topics:
- First (and a half) Session: General Setting
- Censored data setting
- Estimation of survivor functions
- Survival analysis models
- Second session: Comparison of Two Samples
- Logrank statistic
- Nonproportional hazards
- Weighted logrank statistics
- Third session: Sequential Analysis
- Stopping rules
- Weighted logrank statistics in nonproportional hazards
- Reweighted statistics
|
|
3
|
|
|
4
|
|
|
5
|
|
|
6
|
|
|
7
|
- I claim that
- Statistical analyses should be driven by the scientific questions they
are meant to answer
- Before addressing limitations imposed by our sampling scheme (e.g.,
missing data, sequential analysis), we should review the extent to
which our practice adheres to those goals
|
|
8
|
- Statistics is about science.
- Science is about proving things to people.
- Other scientists
- Community at large
|
|
9
|
- A well designed study
- Discriminates between the most important, viable hypotheses
- “Discriminates” defined by what convinces your audience
- Is equally informative for all possible study results
- Binary search using prior probability of being true
- Also consider simplicity of experiments, time, cost
|
|
10
|
- Ultimately, scientific questions are most often concerned with
investigating cause and effect
- E.g., in biomedical settings:
- What are the causes of disease?
- What are the effects of interventions?
|
|
11
|
- In the studies considered here, we define
- Some “primary outcome” measurement
- A “response variable” in regression
- Groups that are homogeneous with respect to the level of some factor(s)
- Predictor of interest
- Effect modifiers
- Confounders
- Precision variables
|
|
12
|
- The primary outcome can be derived from more than one measured variable
- E.g., for repeated measurements made on the same experimental unit
- Contrast across repeated measurements
- Weighted average of repeated measurements
- E.g., for random process defined by longitudinal follow up of
experimental units
- Contrast across time
- Weighted average over time
- Time until an event
|
|
13
|
- The specified level of some factor will cause outcome measurements that
are
|
|
14
|
- Truly determining causation requires a suitable interventional study
(experiment)
- Statistical analyses tell us about associations
- Associations in the presence of an appropriate experimental design
allows us to infer causation
- But even then, we need to be circumspect in identifying the true
mechanistic cause
- E.g., a treatment that causes headaches, and therefore aspirin use,
may result in lower heart attack rates due entirely to the use of
aspirin
|
|
15
|
- The group with the specified level of some factor will have outcome
measurements that are
|
|
16
|
- Conditions of scientific studies might make answering questions
difficult even when study results are deterministic
- Difficulties in isolating specific causes
- E.g., isolating REM sleep from total sleep
- E.g., interactions between genetics and environment
- Difficulties in measuring potential effects
- E.g., measuring time to survival
- length of study
- competing risks
|
|
17
|
- Litmus Test # 1:
- If the scientific question cannot be answered by an experiment when
outcomes are entirely deterministic, there is NO chance that statistics
can be of any help.
|
|
18
|
- There is, of course, usually variation in outcome measurements across
repetitions of an experiment
- Variation can be due to
- Unmeasured (hidden) variables
- E.g., mix of etiologies, duration of disease, comorbid conditions,
genetics when studying new cancer therapies
- Inherent randomness
- (as dictated by quantum theory)
|
|
19
|
- The group with the specified level of some factor will tend to have
outcome measurements that are
|
|
20
|
- In order to be able to perform analysis we must define “will tend to
have”
- Probability model for response
- Nonparametric, semiparametric, parametric
- (Looking ahead: I am a big proponent of nonparametric interpretations of
statistical analyses)
|
|
21
|
- In general, the space of all probability distributions is not totally
ordered
- There are an infinite number of ways we can define a tendency toward a
“larger” outcome
- This can be difficult to decide even when we have data on the entire
population
- Ex: Is the highest paid occupation in the US the one with
- the higher mean?
- the higher median?
- the higher maximum?
- the higher proportion making $1M per year?
|
|
22
|
- Litmus Test # 2:
- If the scientific researcher cannot decide on an ordering of
probability distributions which would be appropriate when measurements
are available on the entire population, there is NO chance that
statistics can be of any help.
|
|
23
|
- Typically we order probability distributions on the basis of some
summary measure
- Statistical hypotheses are then stated in terms of the summary measure
- Primary analysis based on detecting an effect on (most often) one
summary measure
- Avoids pitfalls of multiple comparisons
- Especially important in a regulatory environment
|
|
24
|
- What I call “summary measures”, others might call “parameters”
- “Parameters” suggests use of parametric and semiparametric statistical
models
- I am generally against such analysis methods
- “Functionals” is probably the best word
- “Functional”= anything computed from a cdf
- But too much of a feeling of “statistical jargon”
|
|
25
|
- Many times, statistical hypotheses are stated in terms of summary
measures for univariate (marginal) distributions
- Means (arithmetic, geometric, harmonic, …)
- Medians (or other quantiles)
- Proportion exceeding some threshold
- Odds of exceeding some threshold
- Time averaged hazard function (instantaneous risk)
- …
|
|
26
|
- Comparisons across groups then use differences or ratios
- Difference / ratio of means (arithmetic, geometric, …)
- Difference / ratio of proportion exceeding some threshold
- Difference / ratio of medians (or other quantiles)
- Ratio of odds of exceeding some threshold
- Ratio of hazard (averaged across time?)
- …
|
|
27
|
- Other times groups are compared using a summary measure for the joint
distribution
- Median difference / ratio of paired observations
- Probability that a randomly chosen measurement from one population
might exceed that from the other
- …
|
|
28
|
- The distinction between marginal versus joint summary measures impacts
comparisons across studies
- Most often (always?) transitivity is not guaranteed unless comparisons
can be defined using marginal distributions
- Intransitivity: Pairwise comparisons might suggest
- A > B, and
- B > C, but
- C > A
|
|
29
|
- While I claim that the choice of the definition for “tends to be larger”
is primarily a scientific issue, statisticians do usually play an
important role
- Statisticians do explain how different summary measures capture key
features of a probability distribution
|
|
30
|
- Choice of Summary Measure
- for Inference
|
|
31
|
- I have claimed that
- We usually address scientific questions using summary measures of
probability distributions
- I now claim that
- Selection of a summary measure is best based on scientific criteria
- Relevance to this course: With censored data, we often choose summary
measures that are not the logical choice from a scientific standpoint
|
|
32
|
- Consider survival with a particular treatment used in renal dialysis
patients
- Extract data from registry of dialysis patients
- To ensure quality, only use data after 1995
- Incident cases in 1995: Follow-up 1995 – 2002 (8 years)
- Prevalent cases in 1995: Data from 1995 - 2002
- Incident in 1994: Information about 2nd – 9th
year
- Incident in 1993: Information about 3rd – 10th
year
- …
- Incident in 1988: Information about 8th – 15th
year
|
|
33
|
- Methods to account for censoring/truncation
- Descriptive statistics using Kaplan-Meier
- Options for inference
- Parametric models
- Semiparametric models
- Proportional hazards, etc.
- Nonparametric
- Weighted rank tests: logrank, Wilcoxon, etc.
- Comparison of Kaplan-Meier estimates
|
|
34
|
|
|
35
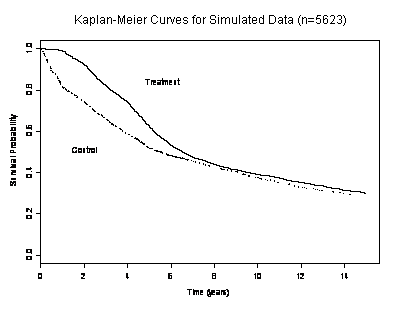
|
- Proportional hazards analysis estimates a Treatment : Control hazard
ratio of
- A: 2.07 (logrank P = .0018)
- B: 1.13 (logrank P = .0018)
- C: 0.87 (logrank P = .0018)
- D: 0.48 (logrank P = .0018)
- Lifelines:
- 50-50? Ask the audience? Call a friend?
|
|
36
|
- Proportional hazards analysis estimates a Treatment : Control hazard
ratio of
- B: 1.13 (logrank P = .0018)
- C: 0.87 (logrank P = .0018)
- Lifelines:
- 50-50? Ask the audience? Call a friend?
|
|
37
|
- How could you have known this?
- In PH, the standard error of log hazard ratio estimates is
approximately 2 divided by the square root of the number of events.
- A P value of .0018 corresponds to | Z | = 3.13
- log(2.07) = -log(0.48) is approximately 0.7
- 3 x 2 / .7 is about 8.4
- Number of deaths would be about 72
- We had 5000+ subjects with survival estimated down to 30%
|
|
38
|
- We choose some summary measure of the probability distribution according
to the following criteria (in order of importance)
- Scientifically (clinically) relevant
- Also reflects current state of knowledge
- Is likely to vary across levels of the factor of interest
- Ability to detect variety of changes
- Statistical precision
- Only relevant if all other things are equal
|
|
39
|
- E.g., Is the arithmetic mean’s sensitivity to outliers desirable or
undesirable?
- Do we want to detect better infant mortality?
- Does making one person immortal make up for killing others
prematurely?
- E.g., Is the scientific importance of a difference in distribution best
measured by the proportion exceeding some threshold?
- Is an increase in survival time only important if the patient
eventually makes it out of intensive care?
|
|
40
|
- The overwhelming majority of statistical inference is based on means
- Means of continuous random variables
- t test, linear regression
- Proportions (means of binary random variables)
- Rates (means) for count data
|
|
41
|
- Rationale
- Scientific relevance
- Measure of “central tendency” or “location”
- Related to totals, e.g. total health care costs
- Plausibility that it would differ across groups
- Sensitive to many patterns of differences in distributions
(especially in tails of distributions)
- Statistical properties
- Distributional theory known
- Optimal (most precise) for many distributions
- (Ease of interpretation?)
|
|
42
|
- Lack of scientific relevance
- The mean is not defined for nominal data
- The mean is sensitive to differences that occur only in the tail of
the distribution
- E.g., increasing the jackpot in Lotto makes one person richer, but
most people still lose
- Small differences may not be of scientific interest
- Extend life expectancy by 24 hours
- Decrease average cholesterol in patients with familial
hypercholesterolemia by 20 mg/dl
|
|
43
|
- Intervention unlikely to affect the mean
- Sometimes we are interested in controlling variability
- E.g., thermostats are designed to maintain house temperature within a
certain range
- E.g., control of blood glucose in diabetics?
- (This is not typically a major criterion for avoiding the mean: It is
rare that the mean is not affected by an intervention.)
|
|
44
|
- Statistical criteria
- In the presence of heavy tails (outliers)
- the mean is not estimated with high precision
- asymptotic distributional theory may not yet hold
- When adjusting for covariates, it may be unreasonable to expect the
mean to show constant differences across subgroups
- Especially invoked with binary data
- (we most often use the odds instead)
|
|
45
|
- Many of the reasons used to justify other tests are based on
misconceptions
- The validity of t tests does NOT depend heavily upon normally
distributed data
- Modern computation allows exact small sample inference for means in
same manner as used for other tests
- The statistical theory used to demonstrate inefficiency of the mean is
most often based on unreasonable (and sometimes untestable)
assumptions
|
|
46
|
- Common teaching:
- A nonparametric alternative to the t test
- Not too bad against normal data
- Better than t test when data have heavy tails
- (Some texts refer to it as a test of medians)
|
|
47
|
- In general, the t test and the Wilcoxon are not testing the same summary
measure
- Wilcoxon test statistic based on Pr(X > Y)
- Null distribution is a permutation test
- Wrong size as a test of Pr(X > Y) = ½
- (unless a semi-parametric model holds on some scale)
- (this can be fixed by modifying the null variance)
- Inconsistent test of F(t) = G(t)
- An infinite sample size may not detect the alternative
- (And the Wilcoxon is not transitive)
|
|
48
|
- Efficiency theory derived when a shift model holds for some monotonic
transformation
- If propensity to outliers is different between groups, the t test may
be better even with heavy tails
|
|
49
|
- In any case, the decision regarding which parameter to use as the basis
for inference sould be made prior to performing any analysis directly
related to the question of interest
- Basing decisions regarding choice of analysis method on the observed
data will tend to inflate the type I error
- Decrease our confidence in our statistical conclusions
|
|
50
|
|
|
51
|
- I claim
- Censored data results from a particular choice of sampling scheme
- Usually such a sampling scheme is necessary due to logistical
constraints
- There is nothing inherent in the mere presence of censored data that
need alter the question which is deemed scientifically most important
|
|
52
|
- My task, therefore, is to discuss the ways that we can answer our
scientific questions in the presence of censored data
- How do we make inference about the summary measures of greatest
interest?
- Sometimes, the presence of censored data does make us modify the
summary measure used.
- Almost always, the presence of censored data requires that we estimate
those summary measures with different computation formulas
|
|
53
|
|
|
54
|
- A special type of missing data
- The exact value is not always known
- Right censoring:
- For some observations it is only known that the true value exceeds
some threshold
- Left censoring:
- For some observations it is only known that the true value is below
some threshold
- Interval censoring:
- For some observations it is only known that the true value is between
some thresholds
|
|
55
|
- A clinical trial is conducted to examine aspirin in prevention of
cardiovascular mortality
- 10,000 subjects are randomized equally to receive either aspirin or
placebo
- Subjects are randomized over a three year period
- Subjects are followed for fatal events for an additional three year
period following accrual of the last subject
|
|
56
|
- At the end of the clinical trial
- Some subjects have been observed to die
- True time to death is known for these subjects
- Most subjects are likely to be still alive
- Death times of these subjects are only known to be longer than the
observation time
- “(Right) Censored observations”
|
|
57
|
- Cannot ignore
- These are our treatment successes
- Cannot just treat as binary (live/die) data:
- Potential time of follow-up (censoring time) differs across subjects
due to time of study entry
- Confounding vs loss of precision
- (Censored data may also arise due to loss to follow-up, e.g., moved
away)
- (Could figure out whether alive/dead at earliest censored observation,
but this is inefficient and may not answer the question of interest)
|
|
58
|
|
|
59
|
|
|
60
|
- I try to build an intuitive feel for
- The information present in the censored data, and
- How that information can be used to estimate the distribution of
response
|
|
61
|
- Hypothetical study of subject survival
- Subjects accrued to study and followed until time of analysis
- Study done at three centers, which started the studies in three
successive years
- Censoring time thus differs across centers
|
|
62
|
- Staggered study entry by site
- Accrual
Group
- Year A B C
- 1990 On study 100 -- --
- Died 43
- Surviving 57
- 1991 On study 57 100 --
- Died 27 53
- Surviving 30 47
- 1992 On study 30 47 100
- Died 13 22 55
- Surviving 17 25 45
|
|
63
|
- Realign data according to time on study
- Accrual
Group
- Year A B C
- 1 On study 100 100 100
- Died 43 53 55
- Surviving 57 47 45
- 2 On study 57 47 --
- Died 27 22
- Surviving 30 25
- 3 On study 30 -- --
- Died 13
- Surviving 17
|
|
64
|
- Accrual
Group
- Year A B C Combined
- 1 On study 100 100 100 300
- Died 43 53 55 151
- Surviving 57 47 45 149
- 2 On study 57 47 -- 104
- Died 27 22 49
- Surviving 30 25 55
- 3 On study 30 -- -- 30
- Died 13 13
- Surviving 17 17
|
|
65
|
- Sampling scheme causes (informative) missing data
- Potentially, we might want to estimate three year survival
probabilities
- Different centers contribute information for varying amounts of time
- One year survival can be estimated at A, B, C
- Two year survival can be estimated at A, B
- Three year survival can be estimated at A
|
|
66
|
- WRONG: Ignore missing
- E.g., 17 of 300 subjects alive at three years
- RIGHT BUT WRONG QUESTION: Use data only up to earliest censoring time
- E.g., 149 of 300 subjects alive at one year
- RIGHT BUT INEFFICIENT: Use only center A
- E.g., 17 of 100 subjects alive at three years
|
|
67
|
- RIGHT AND EFFICIENT
- Use all available data to estimate that portion of survival for which
it is informative
- Use Centers A, B, and C to estimate one year survival
- Use Centers A and B to estimate proportion of one-year survivors who
survive to two years
- Use Center A to estimate proportion of two-year survivors who survive
to three years
|
|
68
|
- Properties of probabilities
- Probability of event A and B occurring is product of
- Probability that A occurs when B has occurred
- Probability that B has occurred
|
|
69
|
- For times T1 < T2 , probability of surviving
beyond time T2 is the product of
- Probability of surviving beyond time T2 given survival
beyond time T1, and
- Probability of surviving beyond time T1
|
|
70
|
- Estimate conditional probability of survival within each time interval
- Condition on surviving up until the start of the time interval
- Denominator is number of subjects at start of interval
- Numerator is deaths during the interval
|
|
71
|
- Consistent estimates of survival probabilities depend on
- The subjects available at the start of each time interval must be a
random sample of the population suriviving to that time
- “Noninformative censoring”
- cf: Nonignorable missing, but noninformative censoring
|
|
72
|
- Estimate probability of survival at the endpoint of each time interval
- Multiply the conditional probabilities for all intervals prior to the
time point of interest
|
|
73
|
- Within interval conditional probabilities
- Use A, B, C to estimate Pr(T
> 1)
- Use A, B to estimate Pr(T
> 2 | T > 1)
- Use A to estimate Pr(T
> 3 | T > 2)
- Multiply to obtain unconditional cumulative survival
- Pr(T > 1)
- Pr(T > 2) = Pr(T > 2 | T
> 1) Pr(T > 1)
- Pr(T > 3) = Pr(T > 3 | T
> 2) Pr(T > 2)
|
|
74
|
- Accrual
Group
- Year A B C Combined
- 1 On study 100 100 100 300
- Died 43 53 55 151
- Surviving 57 47 45 149
- 2 On study 57 47 -- 104
- Died 27 22 49
- Surviving 30 25 55
- 3 On study 30 -- -- 30
- Died 13 13
- Surviving 17 17
|
|
75
|
- Survival
Probabilities
- Yr Combined Each Year Cumulative
- 1 On study 300
- Died 151
- Surviving 149 149/300 = 49.67% 49.67%
- 2 On study 104
- Died 49
- Surviving 55
55/104 = 52.88%
.4967*.5288 = 26.27%
- 3 On study 30
- Died 13
- Surviving 17
17/ 30 = 56.67%
.2627*.5667 = 14.88%
|
|
76
|
- Intuitively, these estimates would provide greater precision, because
they are based on more data than using Center A alone
- We can show this exactly using confidence intervals
|
|
77
|
- For notational convenience
|
|
78
|
- For notational convenience
|
|
79
|
- Maximum likelihood estimates for
- Conditional survival probability within intervals
- Unconditional survival probability
|
|
80
|
- Sums are easier to work with than products
- The log transformed unconditional survival probability is the sum of
log transformed conditional survival probabilities
|
|
81
|
- We will find the standard error of the log transformed survival
probabilities by
- Estimating each conditional survival probability and finding the
variance of the log transformed estimates
- Invoking noninformative censoring to argue that the sum of our log
transformed estimates must have the same distribution as the sum of log
transformed independent estimates
|
|
82
|
- From the laws of expectation, for the jth interval
|
|
83
|
- From the central limit theorem
|
|
84
|
|
|
85
|
- In the presence of noninformative censoring, the risk set in any
interval should look like a random sample of the population at risk
- Estimates of the conditional probability of survival for the intervals
should be uncorrelated
|
|
86
|
- Using the large sample approximation with plug-in estimates for standard
errors
|
|
87
|
- Note the improved precision (and accuracy)
- Narrower CI even for the third year estimates
- Survival
Probabilities (95% CI)
- Yr Site A Only Combined
- 1 0.570 (0.473, 0.667) 0.497 (0.443, 0.557)
- 2 0.300 (0.210, 0.390) 0.263 (0.212, 0.325)
- 3 0.170 (0.096, 0.244) 0.149 (0.102, 0.217)
|
|
88
|
- SE for the survival probabilities by a second application of the delta
method
|
|
89
|
- Three common methods for CI
- Based on log ( S(t) )
- Based on Greenwood’s formula
- Based on log ( - log ( S(t) ) )
- These intervals will always be between 0 and 1
|
|
90
|
- Product Limit
- (Kaplan-Meier)
- Estimates
|
|
91
|
- I introduce the nonparametric estimate of survivor functions, by making
analogy with the previous example
- I also provide an alternative derivation that provides intuition about
the assumption of noninformative censoring
|
|
92
|
- In the actuarial (e.g., insurance) setting
- The time intervals are often chosen by years, decades, etc.
- The data are presented for each year as
- Nj: Number of
subjects at risk at start of interval
- Cj: Number censored
during interval
- (these will contribute half a person-year)
- Dj: Number of events
in interval
|
|
93
|
- Computation of probability of survival
|
|
94
|
- Computation of probability of survival (cont.)
|
|
95
|
- With more precisely measured individual data
- The time intervals are defined by unique observation times
- The data are presented for each year as
- Nj: Number of subjects at risk
at start of interval
- Dj: Number of events at end of
interval
- (Note no censoring or events during interval by definition)
- (Note also that for ties, censoring occurs after deaths)
|
|
96
|
- Computation of probability of survival
|
|
97
|
|
|
98
|
- Note that in the above definition
- An interval which ends in a censored observation with no observed
events has conditional probability of surviving within the interval is
1.
- If the largest observation time is censored, the KM (PLE) survivor
function never goes to zero
- We generally regard the KM (PLE) survivor function to be undefined for
times beyond the largest observation time in this situation
|
|
99
|
- Properties
- The KM (PLE) survivor functions can be shown to be
- Consistent: As sample sizes go to infinity, they estimate the true
value
- Nonparametric maximum likelihood estimates
- (but usual asymptotic theory for regular, parametric MLE’s does not
necessarily hold)
|
|
100
|
- The KM (PLE) survivor functions can also be derived as the
- Self-consistent estimator
- (see Miller, Survival
Analysis)
- “Redistribute to the right” estimator
- Provides intuition regarding noninformative censoring
|
|
101
|
- Basic idea
- Recall the empirical cdf assigns probability 1/n to each observation
- Each subject in a sample is representative of 1/n of the population
- A censored observation should be equally likely to have event time like
any of the remaining uncensored observations
- Recursively redistribute the mass of each censored observation among
the subjects remaining at risk
|
|
102
|
- Data: 1, 3, 4*, 5, 7*, 9, 10 (asterisk means censored)
- Initially: each point has mass 1/7
- Determine probability of events at earliest observed (uncensored) event
times
- Pr (T = 1) = 1/7
- Pr (T = 3) = 1/7
|
|
103
|
- Censored observation at 4
- Divide the mass at 4 equally among the remaining subjects at risk
- Now mass of 1/7 + 1/28 = 5/28 for each of 5, 7, 9, 10
- Determine probability of events at next observed (uncensored) event
times
|
|
104
|
- Censored observation at 7
- Divide the mass at 7 equally among the remaining subjects at risk
- Now mass of 5/28 + 5/56 = 15/56 for each of 9, 10
- Determine probability of events at next observed (uncensored) event
times
- Pr (T = 9) = 15/56
- Pr (T = 10) = 15/56
|
|
105
|
- Risk Sets and
- Hazard Functions
|
|
106
|
- I claim that
- Our ability to address scientific questions with censored data is
heavily dependent upon the assumption of noninformative censoring
- Noninformative censoring guarantees that we can estimate the hazard
function in a consistent fashion
- Hence, understanding the role of risk sets and estimation of the hazard
function is crucial to interpreting the most commonly used survival
analysis methods
|
|
107
|
- From the approach to nonparametric estimation of survival curves we see
the importance of the hazard function
- Hazard = instantaneous risk of failure
- Conditional upon being still alive, what is the probability (rate) of
failing in the next instant
|
|
108
|
|
|
109
|
- The survivor function (and, hence, the cdf) is uniquely determined by
the hazard and vice versa
|
|
110
|
- The intuitive estimator of the hazard function is thus the conditional
probability of failure at each point in time
|
|
111
|
- Survival analysis often focuses on the “risk set” at each time
- “Risk set at time t”= the set of subjects in the sample who are at risk
for failure at t
- These subjects can be used to compute and compare hazard functions
and, hence, survival probabilities
|
|
112
|
- Analyses based on hazard functions afford the opportunity to allow
sampling schemes which sample the population at risk at each time
- Advantages:
- More efficient use of available data
- Time-varying covariates
- Disadvantages:
- Less intuitive summary measures
- Temptation to use time-varying covariates
|
|
113
|
|
|
114
|
- I claim that
- The most commonly used methods for censored data have straightforward
analogues in the urn model used in classical probability
|
|
115
|
- Balls in an urn of various colors and patterns
- Balls might represent people in a study
- At any given time, the balls that are in the urn are therefore the
risk set
- Colors and patterns represent risk factors
|
|
116
|
- Periodically, I come in and choose a ball from the urn and take it
- When a ball is chosen it fails
- My predilection for choosing certain colors or patterns identifies true
risk factors
- Characteristics of the balls that I do not notice have no effect on
survival probabilities
|
|
117
|
- A certain color/pattern must be my favorite if
- (Time based observations)
- I come in more often when that color/pattern is in the urn
- You need not consider what else is in the urn
- (Risk set based observations)
- I choose that color/pattern with a frequency disproportionate to its
frequency in the urn
- If I am blind to a characteristic, my choices should look like random
sampling
- You need not consider the times that I come in
|
|
118
|
- Two general (semi)parametric probability models used in survival
analysis
- Accelerated failure time models
- Proportional hazards models
- Consider relations among hazards
- (Additive hazards models also used, but less frequently)
|
|
119
|
- Two groups that differ in some risk factor have survivor functions
related by a parameter measuring acceleration or deceleration of time
- E.g.,
- A smoker ages twice as fast as a nonsmoker
- Each human year is seven dog years
|
|
120
|
- Two groups that differ in some risk factor have survivor functions
related by a parameter measuring increased hazard
- E.g.,
- At any given time, a smoker is ten times more likely to develop lung
cancer as a nonsmoker
|
|
121
|
- As a scientist you may
- Observe
- When I come into the room and take a ball,
- The colors/patterns on all the balls in the urn, and
- The color/patterns on the ball that I take
- Experiment
- Change the compostion in the urn and see
- Whether I come in the room more or less often, and
- The lengths to which I might go to find balls with certain colors or
patterns by restricting my choices
|
|
122
|
- Censoring and time-varying covariates are analogous to changes in the
composition of the urn
- Censoring = removing balls from the urn
- Time-varying covariates = repainting the balls or adding different
balls
|
|
123
|
- Altering the risk set can be problematic
- Recall that in order for survival estimates to be consistent, the risk
set in the sample must look like a random sample from the population
- You should not selectively remove or change balls that were (for their
risk factors) particularly more likely or less likely to be chosen
- If you notice that I search the urn from top to bottom,
- Don’t just change the balls sitting at the top of the urn
- Make sure you stir the urn after each change
|
|
124
|
- Time-varying covariates are far more easily implemented in the hazard
based models
- Risk set approach makes this easy
- However, scientifically we run the risk of overfitting our data using
variables we are less interested in
- A priest delivering last rites is highly predictive of death and that
may obscure that it was a gunshot wound that led to the death
|
|
125
|
|
|
126
|
- I claim that
- Noninformative censoring is a crucial, but untestable, assumption
- Hence, it is important to think about situations where it might not be
satisfied
|
|
127
|
- Censoring must not be informative about subjects who were either more or
less likely to have an event in the immediate future
- The censored individuals must look like a random sample of those
individuals at risk at the time of censoring
- (Later we shall say that they are a random sample from all subjects at
risk having similar modeled covariates)
|
|
128
|
- Subjects in a clinical trial are withdrawn due to treatment failure
(likely they would die sooner than those remaining)
- Subjects in a clinical trial in a fatal condition are lost to follow up
when they go on vacation (likely they are healthier than those
remaining)
|
|
129
|
- Leukemia patients in a clinical trial of bone marrow transplantation
are censored if they die of infections rather than dying of cancer (the
subjects who died of infections might have had a more effective regimen
to wipe out existing cancer)
|
|
130
|
- As a general rule it is impossible to use the data to detect informative
censoring
- The necessary data is almost certainly missing in the data set
- In some cases, it is impossible to ever observe the missing data
- Nonfelines can only die once
- We cannot observe whether subjects dying of one cause are more or less
likely to die of another if we cure them of the first cause
|
|
131
|
- This last situation is often referred to as “Competing Risks”
- Some “nuisance” event sometimes precludes your ability to ever observe
the event of interest
- In the presence of competing risks, we must decide how best to address
the scientific question of interest
|
|
132
|
- Consider a study of smoking as a risk factor for incidence of cancer
- Possible causes of censored observations
- Subject still alive at time of data analysis
- Subject lost to follow-up during study
- Subject died in airline accident
- Subject died in single car accident
- Subject died of MI
- Subject died of emphysema
|
|
133
|
- Time to cancer, but competing risk of death
- Suppose we censor deaths
- If deaths represent noninformative censoring
- People who died of, say, MI neither more nor less likely to get
cancer in the near term
- Estimates desired hazard rate
- If deaths represent informative censoring
- Estimates cause specific hazard in presence of unchanged risk of
competing event
- Results are not generalizable to a population with an altered risk of
death
|
|
134
|
- Model informative censoring
- Model must be based on untestable assumptions
- Event free survival
- Like censoring deaths if competing risk hazard low
- Like censoring deaths if everyone gets cancer first
- Loss of power if truly noninformative censoring
- Wilcoxon like statistic
- Rank first on death times; break ties with cancer dx
- Like survival only if everyone dies
- Survival only
- Not really the question, especially if competing risk hazard is high
|
|
135
|
|
|
136
|
- I claim that
- The hazard based methods for the analysis of censored data have the
attractive capability to model time-varying covariates
- The difficulties of choosing the appropriate model to address a
scientific question is magnified manifold when considering time-varying
covariates
|
|
137
|
- In a typical study, we compare the distribution of some outcome across
groups defined at the start of the study
- Example: Risk of hang gliding
- Identify two groups
- Follow survival experience over time
|
|
138
|
- What if a coward obtains courage?
- Misclassification will attenuate the true effect of hang gliding on
survival
- Biased estimates
- Less precision
|
|
139
|
- We cannot divide the sample into groups according to lifetime habits
- Suppose we consider
- Ever hang glided (hung glide?) vs Constant coward
- We might detect spurious associations due to “survivorship”
- If we started study at birth, we might find hang gliding is beneficial
- Most people don’t start hang gliding until teenaged
- We would detect the fact that hang gliders survived at least that
long
|
|
140
|
- Let each subject contribute observation time to the appropriate group
according to covariate at the relevant time
- Proportional hazards model
- Easily done, if noninformative censoring results
- Accelerated failure time model
- Difficult due to need to integrate hazards over disjoint intervals
|
|
141
|
- Issues related to the use of time-varying covariates are analogous to
those when deciding to adjust for any variable
- Can regard measurements made at different times as different covariates
- Need to consider
- Causal pathway of interest
- Confounding (bias)
- Precision
- Time aspect does increase the dimensionality
|
|
142
|
- Possibility that impending event causes informative censoring
(confounding?)
- Types of variables
- Extrinsic: Unaffected by individual decisions
- As a rule, time-varying extrinsic variables will not cause
informative censoring
- E.g., Air pollution on a given day in an asthma study
- (providing it does not affect relocation)
- Intrinsic: Potentially affected by impending event
|
|
143
|
- Example: Scientific interest in
causal pathways between marijuana use and heart attacks (MI)
- Pictorial representation of hypothetical causal effect of marijuana
on MI that might be of scientific interest
|
|
144
|
- Statistical analysis can only detect associations reflecting causation
in either direction
- Only experimental design and understanding of the variables allows us
to infer cause and effect
- Statistical analysis will identify causation in either direction
|
|
145
|
- In an observational study, we cannot thus be sure which causative
mechanism an association might represent
- Either of these mechanisms will result in an association between
marijuana use and MI
|
|
146
|
- Thus, in using statistical associations to try to investigate causation,
we must further consider the role other variables might play
- A statistical association can exist between two variables due to a
network of causal pathways in either direction between the two
variables
|
|
147
|
- Furthermore, an association between two variables exists if they are
each caused by a third variable
- This is the classic case of a confounder that we would like to adjust
for in order to avoid finding spurious associations when looking for
cause and effect
|
|
148
|
- But not all such networks of causal pathways will produce an association
- Two variables are not associated just because they each are the cause
of a third variable
- E.g., no association between marijuana use and MI if the following are
the only pathways
|
|
149
|
- Adjustment for the third variable in this case can produce a spurious
association in this example
- Missing days off work is informative about MI incidence among those who
do not use marijuana
- Among people missing work, marijuana users will have lower incidence
of MI
- The incidence of MI will likely be similar between marijuana users
and nonusers who do not miss work
- The resulting interaction will seem to be an association in an
adjusted analysis
|
|
150
|
- In the previous example, we might know not to adjust for Days Off Work,
because that occurs after the response
- We regard that causes of events must be in the correct temporal
sequence
- However, there are situations where this criterion can be hard to
judge
- Furthermore, there are situations where similarly inappropriate
adjustment of variables can occur with variables measured before the
event
|
|
151
|
- Similar problems can arise from more complicated causal pathways
- Adjustment for Variable C would produce a spurious association
- Note that the association between C and marijuana and C and MI are not
causal, but C can occur before an MI
|
|
152
|
- With time-varying covariates, we have increased opportunity to measure
short term effects
- This is good if that is our interest
- Immediate effects of blood pressure on hemorrhagic stroke
- This is bad if we wanted to assess long acting risk factors
- Chronic effect of asbestos on lung cancer
- A former asbestos worker is still at high risk
|
|
153
|
- Capability for modeling time-varying covariates also increases chances
for modeling a variable in the causal pathway of interest
|
|
154
|
- Adjustment for covariates changes the question being answered by the
statistical analysis
- Adjustment can be used to isolate associations that are of particular
interest
- Adjustment should not be used if the variable represents a “causal
pathway of interest”
|
|
155
|
- Scientific question:
- Marijuana bad in any way?
- Marijuana causes MI by cardiovascular effect?
|
|
156
|
- As illustrated previously, the interpretation of some of the statistics
commonly used in survival analysis is heavily dependent upon the
censoring distribution
- It is very difficult to explore how the changing size of risk sets
might be altering the interpretation of the time-averaged hazard ratio
in a proportional hazards model
|
|
157
|
- Time-varying covariates are definitely of scientific interest
- However, they should not be used casually
- Usually, my first choice is to try to address scientific questions with
fixed covariates
- I will put up with some misclassification, to avoid making mistakes
that are due to incorrect, untestable assumptions
|
|
158
|
- Choice of Summary Measures
- Used for Inference
|
|
159
|
- I claim that
- The presence of censored data is a technical (rather than scientific)
issue raised by the sampling scheme
- Every summary measure of interest in the absence of censored data can
be estimated using censored data in some probability model
- Nonparametric estimation places some limitations on choice of summary
measures
|
|
160
|
- Marginal summary measures
- Means (arithmetic, geometric, harmonic, …)
- Medians (or other quantiles)
- Proportion exceeding some threshold
- Odds of exceeding some threshold
- Time averaged hazard function (instantaneous risk)
- …
|
|
161
|
- Based on marginal distributions
- Difference / ratio of means (arithmetic, geometric, …)
- Difference / ratio of proportion exceeding some threshold
- Difference / ratio of medians (or other quantiles)
- Ratio of odds of exceeding some threshold
- Ratio of hazard (averaged across time?)
- …
- Based on joint distribution
- Median difference / ratio of paired observations
- Probability that a randomly chosen measurement from one population
might exceed that from the other
- …
|
|
162
|
- Options for inference
- Parametric models
- Semiparametric models
- Proportional hazards, etc.
- Nonparametric
- Weighted rank tests: logrank, Wilcoxon, etc.
- Comparison of Kaplan-Meier estimates
|
|
163
|
- Choice of statistical model can affect
- Computational methods for estimating the summary measure
- Precision of summary measure estimates
- Robustness of inference about the summary measure
- Ability to estimate the summary measure
|
|
164
|
|
|
165
|
|
|
166
|
|
|
167
|
- F is known up to some finite dimensional parameter vectors
|
|
168
|
- Commonly used parametric survival models are generally accelerated
failure time models
- Exponential
- Weibull
- Gamma
- Lognormal
- Log logistic
- Families joining several of the above
|
|
169
|
- Weibull distribution
- Log hazard function is linear
- Special case: exponential is constant hazard
- Only distribution both AFT and PH
- Can be motivated as earliest failure of components
- “A chain is as strong as its weakest link”
|
|
170
|
- Gamma distribution
- Special case: exponential is constant hazard
- Can be motivated as time to failure of last component
- Parallel components with exponential lifetimes
|
|
171
|
- Lognormal distribution
- log(T) is normal with mean Φ1 and variance Φ2
|
|
172
|
- Parametric inference generally proceeds through likelihood methods
- MLE found by Newton-Raphson iteration
- Asymptotic distributions from theory of regular problems
|
|
173
|
|
|
174
|
- Advantages
- Can estimate any of the summary measures
- Can handle sparse data
- Disadvantages
- Not robust to other distributions
- Parametric estimates do not generally have easy nonparametric
interpretation
- E.g., lognormal model is not particularly robust
- Little reason to suggest particular distribution
- But motivation does exist for Weibull and Gamma
|
|
175
|
- Exact form of within group distributions are unknown, but related to
each other by some finite dimensional parameter vector
- Full inference only for comparing distributions
- One group’s distn can be found from another group’s and a finite
dimensional parameter
- (Most often: Distributions equal under H0)
- (My definition of
semiparametric models is a little stronger than some statisticians’,
but agrees with commonly used semiparametric survival models)
|
|
176
|
|
|
177
|
|
|
178
|
- Semiparametric inference generally proceeds through estimating equations
- Estimates found by iterative search
- Asymptotic distributions from special theory
|
|
179
|
- Proportional hazards regression based on hazard of observed failure
relative to sum of hazards in the risk set
|
|
180
|
- Estimation of summary measures is generally limited to the parameter
fundamental to the semiparametric model
- Proportional hazards
- Can only make inference about hazard ratio
- Accelerated failure time
- Can only make inference about ratio of quantiles
|
|
181
|
- Advantages
- Can handle sparse data
- More robust than any single parametric model
- Disadvantages
- Not easily interpreted when semiparametric model does not hold
- Little reason to suggest a given risk factor would affect distribution
in only one way
|
|
182
|
|
|
183
|
- (Semi)parametric models are not typically in keeping with the state of
knowledge as an experiment is being conducted
- The assumptions are more detailed than the hypothesis being tested,
e.g.,
- Question: How does the intervention affect the first moment of the
probability distribution?
- Assumption: We know how the intervention affects the 2nd, 3rd, …,
∞ central moments of the probability distribution.
|
|
184
|
- Incorrect parametric assumptions can lead to incorrect statistical
inference
- Precision of estimators can be over- or understated
- Hypothesis tests do not attain the nominal size
- Hypothesis tests can be inconsistent
- Even an infinite sample size may not detect the alternative
- Interpretation of estimators can be wrong
|
|
185
|
- Survival cure model (Ibrahim, 1999, 2000)
- Probability model
- Proportion πi is cured (survival probability 1 at
∞) in the i-th treatment group
- Noncured group has survival distribution modeled parametrically
(e.g., Weibull) or semiparametrically (e.g., proportional hazards)
- Treatment effect is measured by θ = π1 – π0
- The problem as I see it: Incorrect assumptions about the nuisance
parameter can bias the estimation of the treatment effect
|
|
186
|
- Which null hypothesis should we test?
- The intervention has no effect whatsoever
- The intervention has no effect on some summary measure of the
distribution
|
|
187
|
- What should the distribution of the data under the alternative
represent?
- Counterfactual
- An imagined form for F(t), G(t) if something else were true
- Empirical
- The most likely distribution of the data if the alternative hypothesis
about were true
|
|
188
|
- The null hypothesis of greatest interest is rarely that a treatment has
no effect
- Bone marrow transplantation
- Women’s Health Initiative
- National Lung Screening Trial
- The empirical alternative is most in keeping with inference about a
summary measure
|
|
189
|
- The above views have important ramifications regarding the computation
of standard errors for statistics under the null
- Permutation tests (or any test which presumes F=G under the null) will
generally be inconsistent
|
|
190
|
- Many mechanisms would seem to make it likely that the problems in which
a fully parametric model or even a semiparametric model is correct
constitute a set of measure zero
- Treatments are often directed to outliers
- Treatments are often only effective in subsets
- Factors affect rates; outcomes measure cumulative effects
|
|
191
|
- Model checking is apparently used by many to allow them to believe that
their models are correct.
- From a recent referee’s report:
- “I know of no sensible statistician (frequentist or Bayesian) who does
not do model checking.”
- Apparently the referee believes the following unproven proposition:
- If we cannot tell the model is wrong, then statistical inference under
the model will be correct
|
|
192
|
- Counter example: Exponential vs Lognormal medians
- Pretest with Kolmogorov-Smirnov test (n=40)
- Power to detect wrong model
- Coverage of 95% CI under wrong model
|
|
193
|
- Model checking particularly makes little sense in a regulatory setting
- Commonly used null hypotheses presume the model fits in the absence of
a treatment effect
- Frequentists would be testing for a treatment effect as they do model
checking
- Bayesians should model any uncertainty in the distribution
- Interestingly, if one does this, the estimate indicating parametric
family will in general vary with the estimate of treatment effect
|
|
194
|
- Form of F is completely arbitrary and unknown within groups
- The summary measure measuring factor effect is just some difference
between distributions
- The summary measure is estimated nonparametrically
- (preferably within groups and then compared across groups)
|
|
195
|
- Typical approaches to compare response across two treatment arms
- Difference / ratio of means (arithmetic, geometric, …)
- Difference / ratio of medians (or other quantiles)
- Median difference of paired observations
- Difference / ratio of proportion exceeding some threshold
- Ratio of odds of exceeding some threshold
- Ratio of instantaneous risk of some event
- Probability that a randomly chosen measurement from one population
might exceed that from the other
- …
|
|
196
|
- Nonparametric: Estimate summary measures from nonparametric empirical
distribution functions
- E.g., use sample median for inference about population medians
- In the presence of censoring, use estimates based on Kaplan-Meier
estimates
- Often the nonparametric estimate agrees with a commonly used
(semi)parametric estimate
- Interpretation may depend on sampling scheme
- In this case, the difference will come in the computation of the
standard errors
|
|
197
|
|
|
198
|
- Depending on the censoring scheme, not all summary measures are
estimable
- The support of the censoring distribution may preclude estimation of
the mean and some quantiles
- Can instead use the mean of the truncated distribution
- “Average increase in days alive during first 5 years”
|
|
199
|
- In most cases, variance estimates can be obtained from the asymptotic
theory of the Kaplan-Meier estimates
- There are still some issues to be solved
- Regression modeling needs to be worked out
- Software is not readily available (Why not?)
|
 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
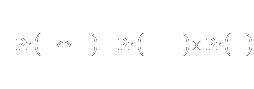{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
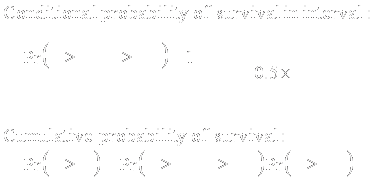{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
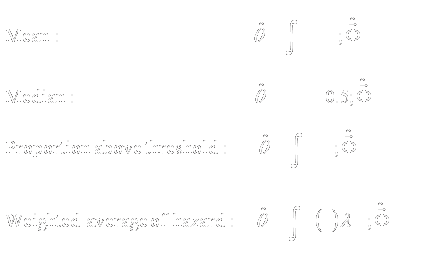{kind=link}
{kind=link}
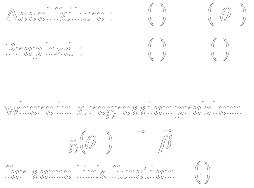{kind=link}
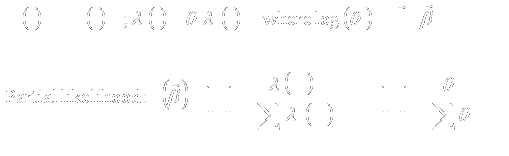{kind=link}
{kind=link}
{kind=link}
{kind=link}
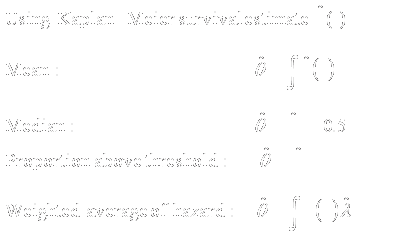{kind=link}
{kind=link}
{kind=link}